MPEG compression
MPEG compression is based on the fact that in a video image up to 95% of the digitaldata consists of repetitions and can be compressed without noticeable loss of quality. MPEG relies on similarities in successive video images, it takes into account the fact that a video image consists mainly of areas and lines or edges, and that the brightness distribution in video images is comparable over several images.
These assumptions result in the algorithm, in which predictions, so called predictions, are implemented on following video images. Areas, edges and brightness values in the prediction deviate only slightly from the original image, which leads to a significant data reduction. However, if the predicted images deviate significantly from the prediction, more data-intensive correction is required.
MPEG works with analog video in the YUV color model. After digitization and color subsampling, the images are divided into 8x8 pixelblocks. By means of DCT transformation, the brightness or color values are converted into frequency parameters and stored in an 8x8 block. The average value of the brightness is stored in the upper left block, and the frequency spectrum of the image content is stored in the other blocks. The detail resolution of the individual data blocks increases continuously until it reaches its maximum in the lower right data block. A downstream quantization of the data is used for further data reduction.
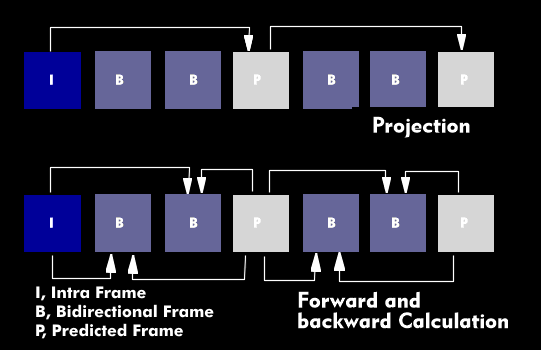
Since successive video pictures are very similar, they are divided into several macroblocks, the so-called Group of Pictures( GOP). Within these groups of pictures, the pictures are compressed sequentially, starting from the data-intensive initial picture of the group, followed by highly compressed pictures and pictures based on a prediction.