text compression
Text compression is a lossless compression with data reduction between 20% and 50%. Two different methods are used. One is based on the statistics of letters and characters, the other is the dictionary method.
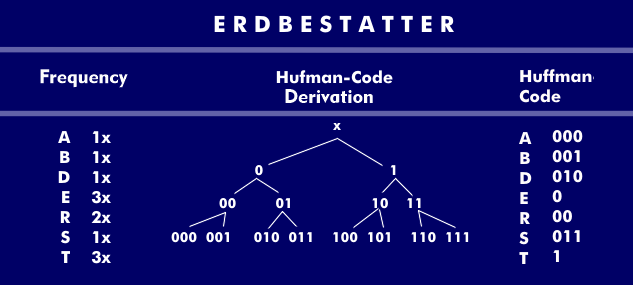
Since texts contain redundancies in letters or words, the goal of text compression is to reduce redundancies. This can refer to letters, digits, characters and binary data as in run-length encoding. On the other hand, variable length encoding can also be used. In this case, short bit sequences are assigned to the most frequently occurring letters, as in the old Morse code, where the letter "e" was signaled only by the short character (dot) the letter "q", on the other hand, by dash-dash-dot-dash. Transferred to text compression, for example, the frequency of the letters occurring in a word is recorded in the Huffman coding and the substitution is derived from this.